深度优先搜索、回溯
题目
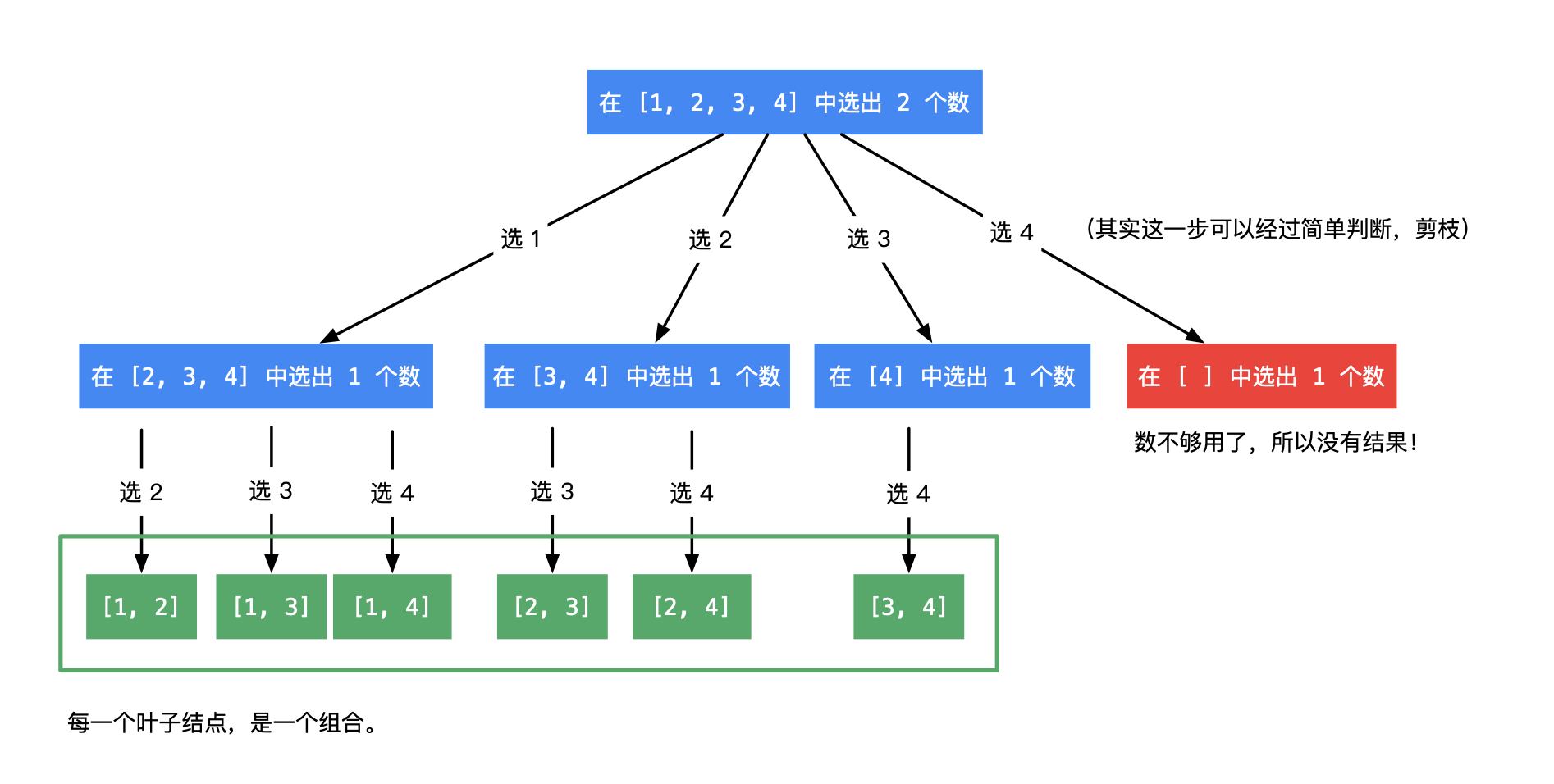
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
示例:
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]题解
方法一:递归回溯
思路与算法
组合:不计较排列顺序,也即[1,2]和[2,1]为同一组合
1 | class Solution: |
1 | a=Solution() |
递归前-->: [1]
递归前-->: [1, 2]
递归前-->: [1, 2, 3]
递归后-->: [1, 2]
递归前-->: [1, 2, 4]
递归后-->: [1, 2]
递归后-->: [1]
递归前-->: [1, 3]
递归前-->: [1, 3, 4]
递归后-->: [1, 3]
递归后-->: [1]
递归前-->: [1, 4]
递归后-->: [1]
递归后-->: []
递归前-->: [2]
递归前-->: [2, 3]
递归前-->: [2, 3, 4]
递归后-->: [2, 3]
递归后-->: [2]
递归前-->: [2, 4]
递归后-->: [2]
递归后-->: []
递归前-->: [3]
递归前-->: [3, 4]
递归后-->: [3]
递归后-->: []
递归前-->: [4]
递归后-->: []
[[1, 2, 3], [1, 2, 4], [1, 3, 4], [2, 3, 4]]递归优化,剪枝
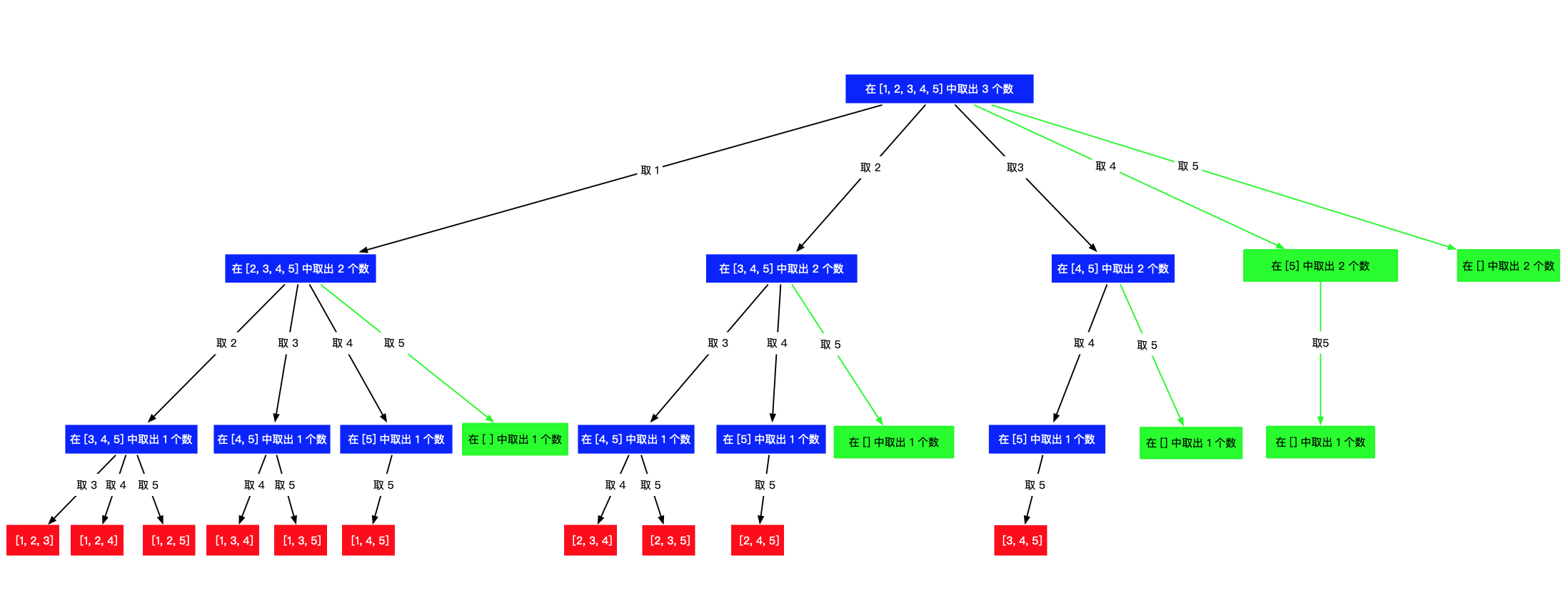
例如:n = 6 ,k = 4。
path.size() == 1 的时候,接下来要选择 3个数,搜索起点最大是 4,最后一个被选的组合是 [4, 5, 6];
path.size() == 2 的时候,接下来要选择 2 个数,搜索起点最大是 5,最后一个被选的组合是 [5, 6];
path.size() == 3 的时候,接下来要选择 1个数,搜索起点最大是 6,最后一个被选的组合是 [6]可以归纳出:
搜索起点的上界 + 接下来要选择的元素个数 - 1 = n也即搜索上界:
搜索上界=n-(k-len(path))+1我们将range(begin,n+1)改为range(begin,n-(k-len(path))+1+1)
1 | class Solution: |
1 | a=Solution() |
递归前-->: [1]
递归前-->: [1, 2]
递归前-->: [1, 2, 3]
递归后-->: [1, 2]
递归前-->: [1, 2, 4]
递归后-->: [1, 2]
递归后-->: [1]
递归前-->: [1, 3]
递归前-->: [1, 3, 4]
递归后-->: [1, 3]
递归后-->: [1]
递归后-->: []
递归前-->: [2]
递归前-->: [2, 3]
递归前-->: [2, 3, 4]
递归后-->: [2, 3]
递归后-->: [2]
递归后-->: []
[[1, 2, 3], [1, 2, 4], [1, 3, 4], [2, 3, 4]]方法二:使用itertools.combinations库
测试发现使用该库的时间效率比较高,故下列是对源码的分析
1 | def combinations(iterable, r): |
1 | nums=[1,2,3] |
[(1, 2), (1, 3), (2, 3)]1 | import itertools |
1 | def combine(n,k): |
[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]参考链接