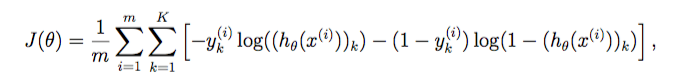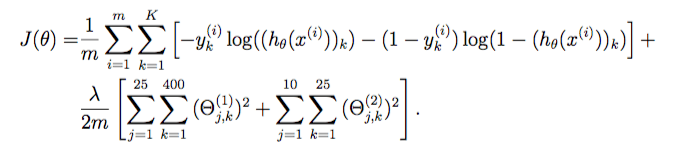对于这个练习,我们将再次处理手写数字数据集,这次使用反向传播的前馈神经网络。 我们将通过反向传播算法实现神经网络代价函数和梯度计算的非正则化和正则化版本。 我们还将实现随机权重初始化和使用网络进行预测的方法。
数据集加载 由于我们在练习3中使用的数据集是相同的,所以我们将重新使用代码来加载数据。
1 2 3 4 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom scipy.io import loadmat
1 2 data = loadmat('ex4data1.mat' ) data
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 16 13:09:09 2011',
'__version__': '1.0',
'__globals__': [],
'X': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'y': array([[10],
[10],
[10],
...,
[ 9],
[ 9],
[ 9]], dtype=uint8)}由于我们以后需要这些(并将经常使用它们),我们先来创建一些有用的变量。
1 2 3 4 X = data['X' ] y = data['y' ] X.shape, y.shape
((5000, 400), (5000, 1))one-hot编码
one hot编
是将类别变量转换为机器学习算法易于利用的一种形式的过程。
示例:
我们也需要对我们的y标签进行一次one-hot 编码。 one-hot 编码将类标签n(k类)转换为长度为k的向量,其中索引n为“hot”(1),而其余为0。 Scikitlearn有一个内置的实用程序,我们可以使用这个。
1 2 3 4 5 6 7 from sklearn.preprocessing import OneHotEncoderencoder = OneHotEncoder(sparse=False ,categories='auto' ) y_onehot = encoder.fit_transform(y) y_onehot.shape
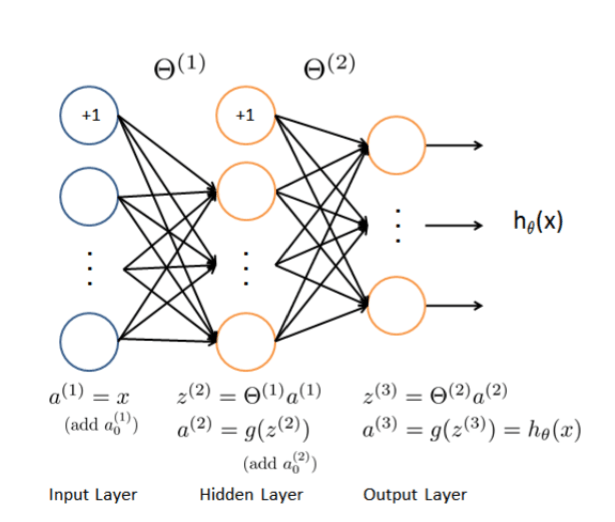
(5000, 10)(array([10], dtype=uint8), array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]))我们要为此练习构建的神经网络具有与我们的实例数据(400 +偏置单元)大小匹配的输入层,25个单位的隐藏层(带有偏置单元的26个),以及一个输出层, 10个单位对应我们的一个one-hot编码类标签。 有关网络架构的更多详细信息和图像,请参阅“练习”文件夹中的PDF。
我们需要实现的第一件是评估一组给定的网络参数的损失的代价函数。 源函数在练习文本中(看起来很吓人)。 以下是代价函数的代码。
sigmoid 函数 g 代表一个常用的逻辑函数(logistic function)为S形函数(Sigmoid function),公式为: $g\left( z \right)=\frac{1}{1+{{e}^{-z}}}$
1 2 def sigmoid (z) : return 1 / (1 + np.exp(-z))
前向传播函数
(400 + 1) -> (25 + 1) -> (10)
1 2 m = X.shape[0 ] np.insert(X,0 ,values=np.ones(m),axis=1 )
array([[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
...,
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.]])1 2 3 4 5 6 7 8 9 10 def forward_propagate (X, theta1, theta2) : m = X.shape[0 ] a1 = np.insert(X, 0 , values=np.ones(m), axis=1 ) z2 = a1 * theta1.T a2 = np.insert(sigmoid(z2), 0 , values=np.ones(m), axis=1 ) z3 = a2 * theta2.T h = sigmoid(z3) return a1, z2, a2, z3, h
代价函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def cost (params, input_size, hidden_size, num_labels, X, y, learning_rate) : m = X.shape[0 ] X = np.matrix(X) y = np.matrix(y) theta1 = np.matrix(np.reshape(params[:hidden_size * (input_size + 1 )], (hidden_size, (input_size + 1 )))) theta2 = np.matrix(np.reshape(params[hidden_size * (input_size + 1 ):], (num_labels, (hidden_size + 1 )))) a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2) J = 0 for i in range(m): first_term = np.multiply(-y[i,:], np.log(h[i,:])) second_term = np.multiply((1 - y[i,:]), np.log(1 - h[i,:])) J += np.sum(first_term - second_term) J = J / m return J
这个Sigmoid函数我们以前使用过。 前向传播函数计算给定当前参数的每个训练实例的假设。 它的输出形状应该与y的一个one-hot编码相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 input_size = 400 hidden_size = 25 num_labels = 10 learning_rate = 1 params = (np.random.random(size=hidden_size * (input_size + 1 ) + num_labels * (hidden_size + 1 )) - 0.5 ) * 0.25 m = X.shape[0 ] X = np.matrix(X) y = np.matrix(y) theta1 = np.matrix(np.reshape(params[:hidden_size * (input_size + 1 )], (hidden_size, (input_size + 1 )))) theta2 = np.matrix(np.reshape(params[hidden_size * (input_size + 1 ):], (num_labels, (hidden_size + 1 )))) theta1.shape, theta2.shape
((25, 401), (10, 26))1 2 a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2) a1.shape, z2.shape, a2.shape, z3.shape, h.shape
((5000, 401), (5000, 25), (5000, 26), (5000, 10), (5000, 10))代价函数在计算假设矩阵h之后,应用代价函数来计算y和h之间的总误差。
1 cost(params, input_size, hidden_size, num_labels, X, y_onehot, learning_rate)
7.1820028858344761 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def sigmoid (z) : return 1 /(1 +np.exp(-z)) def forward_propagate (X,theta1,theta2) : m = X.shape[0 ] a1 = np.insert(X, 0 , values=np.ones(m), axis=1 ) z2 = a1* theta1.T a2 = np.insert(sigmoid(z2),0 ,values=np.ones(m),axis=1 ) z3 = a2 * theta2.T h = sigmoid(z3) return a1,z2,a2,z3,h def cost (params, input_size,hidden_size,num_lables,X,y,learning_rate) : m = X.shape[0 ] X = np.matrix(X) y = np.matrix(y) theta1 = np.matrix(np.reshape(params[:hidden_size*(input_size+1 )],(hidden_size,input_size+1 ))) theta2 = np.matrix(np.reshape(params[hidden_size*(input_size+1 ):],(num_lables,hidden_size+1 ))) a1,z2,a2,z3,h = forward_propagate(X,theta1,theta2) J=0 for i in range(m): first_term = np.multiply(-y[i,:], np.log(h[i,:])) second_term = np.multiply((1 - y[i,:]), np.log(1 - h[i,:])) J += np.sum(first_term - second_term) J = J / m return J input_size= 400 hidden_size= 25 num_labels= 10 learning_rate =1 params = (np.random.random(size=hidden_size * (input_size + 1 ) + num_labels * (hidden_size + 1 )) - 0.5 ) * 0.25 cost(params,input_size,hidden_size,num_labels,X,y_onehot,learning_rate)
7.132323728323127正则化代价函数 我们的下一步是增加代价函数的正则化。 它实际上并不像看起来那么复杂 - 事实上,正则化术语只是我们已经计算出的代价的一个补充。 下面是修改后的代价函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def cost (params, input_size, hidden_size, num_labels, X, y, learning_rate) : m = X.shape[0 ] X = np.matrix(X) y = np.matrix(y) theta1 = np.matrix(np.reshape(params[:hidden_size * (input_size + 1 )], (hidden_size, (input_size + 1 )))) theta2 = np.matrix(np.reshape(params[hidden_size * (input_size + 1 ):], (num_labels, (hidden_size + 1 )))) a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2) J = 0 for i in range(m): first_term = np.multiply(-y[i,:], np.log(h[i,:])) second_term = np.multiply((1 - y[i,:]), np.log(1 - h[i,:])) J += np.sum(first_term - second_term) J = J/m J += (float(learning_rate) / (2 * m)) * (np.sum(np.power(theta1[:,1 :], 2 )) + np.sum(np.power(theta2[:,1 :], 2 ))) return J
1 cost(params, input_size, hidden_size, num_labels, X, y_onehot, learning_rate)
7.137673923569304反向传播 接下来是反向传播算法。 反向传播参数更新计算将减少训练数据上的神经网络误差。 我们需要的第一件事是计算我们之前创建的Sigmoid函数的梯度的函数。
1 2 def sigmoid_gradient (z) : return np.multiply(sigmoid(z), (1 - sigmoid(z)))
现在我们准备好实施反向传播来计算梯度。 由于反向传播所需的计算是代价函数中所需的计算过程,我们实际上将扩展代价函数以执行反向传播并返回代价和梯度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 def backprop (params, input_size, hidden_size, num_labels, X, y, learning_rate) : m = X.shape[0 ] X = np.matrix(X) y = np.matrix(y) theta1 = np.matrix(np.reshape(params[:hidden_size * (input_size + 1 )], (hidden_size, (input_size + 1 )))) theta2 = np.matrix(np.reshape(params[hidden_size * (input_size + 1 ):], (num_labels, (hidden_size + 1 )))) a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2) J = 0 delta1 = np.zeros(theta1.shape) delta2 = np.zeros(theta2.shape) for i in range(m): first_term = np.multiply(-y[i,:], np.log(h[i,:])) second_term = np.multiply((1 - y[i,:]), np.log(1 - h[i,:])) J += np.sum(first_term - second_term) J = J / m J += (float(learning_rate) / (2 * m)) * (np.sum(np.power(theta1[:,1 :], 2 )) + np.sum(np.power(theta2[:,1 :], 2 ))) for t in range(m): a1t = a1[t,:] z2t = z2[t,:] a2t = a2[t,:] ht = h[t,:] yt = y[t,:] d3t = ht - yt z2t = np.insert(z2t, 0 , values=np.ones(1 )) d2t = np.multiply((theta2.T * d3t.T).T, sigmoid_gradient(z2t)) delta1 = delta1 + (d2t[:,1 :]).T * a1t delta2 = delta2 + d3t.T * a2t delta1 = delta1 / m delta2 = delta2 / m grad = np.concatenate((np.ravel(delta1), np.ravel(delta2))) return J, grad
1 2 3 4 5 6 7 a = np.array([[1 , 2 ], [3 , 4 ]]) b = np.array([[5 , 6 ]]) print("111:" ,np.ravel(a)) print("222:" ,np.concatenate((a,b))) print("ddd:" ,np.concatenate((a, b.T), axis=1 )) print("--------" ) np.concatenate((np.ravel(a),np.ravel(b)))
111: [1 2 3 4]
222: [[1 2]
[3 4]
[5 6]]
ddd: [[1 2 5]
[3 4 6]]
--------
array([1, 2, 3, 4, 5, 6])反向传播计算的最难的部分(除了理解为什么我们正在做所有这些计算)是获得正确矩阵维度。 顺便说一下,你容易混淆了A * B与np.multiply(A,B)使用。 基本上前者是矩阵乘法,后者是元素乘法(除非A或B是标量值,在这种情况下没关系)。
1 2 J, grad = backprop(params, input_size, hidden_size, num_labels, X, y_onehot, learning_rate) J, grad.shape
(7.137673923569304, (10285,))矩阵乘法和元素乘法
1 2 3 4 5 6 a = np.matrix(np.array([[1 ,2 ,3 ,3 ]])) b = np.matrix(np.array([[2 ],[3 ],[4 ],[5 ]])) print(a.shape,b.shape) print(a*b) print(np.dot(a,b))
(1, 4) (4, 1)
[[35]]
[[35]]1 2 3 4 a = np.matrix(np.array([[1 ,2 ,3 ,3 ]])) b = np.matrix(np.array([[2 ,4 ,6 ,8 ]])) np.multiply(b,a)
matrix([[ 2, 8, 18, 24]])反向传播正则化 我们还需要对反向传播函数进行一个修改,即将梯度计算加正则化。 最后的正式版本如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def backprop (params, input_size, hidden_size, num_labels, X, y, learning_rate) : m = X.shape[0 ] X = np.matrix(X) y = np.matrix(y) theta1 = np.matrix(np.reshape(params[:hidden_size * (input_size + 1 )], (hidden_size, (input_size + 1 )))) theta2 = np.matrix(np.reshape(params[hidden_size * (input_size + 1 ):], (num_labels, (hidden_size + 1 )))) a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2) J = 0 delta1 = np.zeros(theta1.shape) delta2 = np.zeros(theta2.shape) for i in range(m): first_term = np.multiply(-y[i,:], np.log(h[i,:])) second_term = np.multiply((1 - y[i,:]), np.log(1 - h[i,:])) J += np.sum(first_term - second_term) J = J / m J += (float(learning_rate) / (2 * m)) * (np.sum(np.power(theta1[:,1 :], 2 )) + np.sum(np.power(theta2[:,1 :], 2 ))) for t in range(m): a1t = a1[t,:] z2t = z2[t,:] a2t = a2[t,:] ht = h[t,:] yt = y[t,:] d3t = ht - yt z2t = np.insert(z2t, 0 , values=np.ones(1 )) d2t = np.multiply((theta2.T * d3t.T).T, sigmoid_gradient(z2t)) delta1 = delta1 + (d2t[:,1 :]).T * a1t delta2 = delta2 + d3t.T * a2t delta1 = delta1 / m delta2 = delta2 / m delta1[:,1 :] = delta1[:,1 :] + (theta1[:,1 :] * learning_rate) / m delta2[:,1 :] = delta2[:,1 :] + (theta2[:,1 :] * learning_rate) / m grad = np.concatenate((np.ravel(delta1), np.ravel(delta2))) return J, grad
1 2 J, grad = backprop(params, input_size, hidden_size, num_labels, X, y_onehot, learning_rate) J, grad.shape
(7.137673923569304, (10285,))我们终于准备好训练我们的网络,并用它进行预测。 这与以往的具有多类逻辑回归的练习大致相似。
1 2 3 4 5 6 from scipy.optimize import minimizefmin = minimize(fun=backprop, x0=params, args=(input_size, hidden_size, num_labels, X, y_onehot, learning_rate), method='TNC' , jac=True , options={'maxiter' : 250 }) fmin
fun: 0.36936848574990994
jac: array([-1.94682911e-04, 2.79038111e-06, -8.05264111e-06, ...,
-7.06122696e-04, -9.89911805e-04, -9.76751347e-04])
message: 'Max. number of function evaluations reached'
nfev: 250
nit: 16
status: 3
success: False
x: array([-0.13037322, 0.01395191, -0.04026321, ..., -1.50678966,
-0.13882294, -0.24985413])由于目标函数不太可能完全收敛,我们对迭代次数进行了限制。 我们的总代价已经下降到0.5以下,这是算法正常工作的一个很好的指标。 让我们使用它发现的参数,并通过网络转发,以获得一些预测。
让我们使用它找到的参数,并通过网络前向传播以获得预测。
1 2 3 4 5 6 7 X = np.matrix(X) theta1 = np.matrix(np.reshape(fmin.x[:hidden_size * (input_size + 1 )], (hidden_size, (input_size + 1 )))) theta2 = np.matrix(np.reshape(fmin.x[hidden_size * (input_size + 1 ):], (num_labels, (hidden_size + 1 )))) a1, z2, a2, z3, h = forward_propagate(X, theta1, theta2) y_pred = np.array(np.argmax(h, axis=1 ) + 1 ) y_pred
array([[10],
[10],
[10],
...,
[ 9],
[ 9],
[ 9]], dtype=int64)1 2 3 a=np.array([[10 , 11 , 12 ], [13 , 14 , 15 ]]) np.argmax(a, axis=1 )
array([2, 2], dtype=int64)最后,我们可以计算准确度,看看我们训练完毕的神经网络效果怎么样。
1 2 3 correct = [1 if a == b else 0 for (a, b) in zip(y_pred, y)] accuracy = (sum(map(int, correct)) / float(len(correct))) print ('accuracy = {0}%' .format(accuracy * 100 ))
accuracy = 98.34%我们已经成功地实施了一个基本的反向传播神经网络,并用它来分类手写数字图像。 在下一个练习中,我们将介绍另一个强大的监督学习算法,支持向量机。
参考资料