学习python之pickle详解
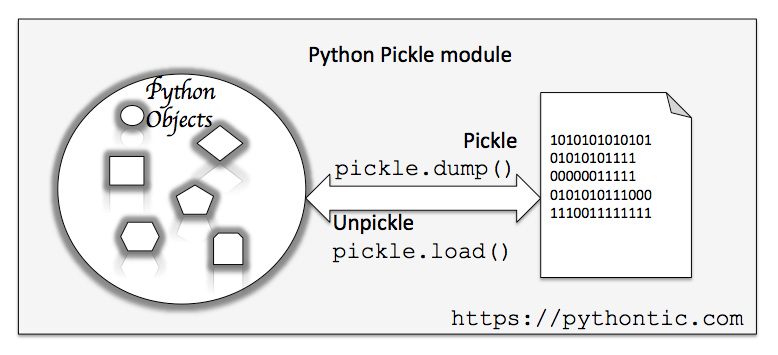
序列化和反序列化
便于存储(序列化过程:将文本信息转为==二进制数据流,易存储在硬盘中==)
反序列化从硬盘读取的数据,可得到原始数据
python程序运行中得到的字符串、列表等数据,要长久保存,方便之后使用(pickle模块可以将对象转换为已知可以传输或存储的格式)
python中序列化和反序列化
将Python对象转换为二级制形式叫做序列化(Pickling)
将二进制数据流恢复为Python对象叫做反序列化(Unpickling)
pickle
提供了一个简单的==持久化==功能,可以将对象以==文件==形式存放在磁盘上
只能在python中使用,可以序列化python中几乎所有的数据类型(列表、字典…)
pickle序列化后的数据,可读性差
pickle序列化和反序列化示例
819pickling_unpickling_example.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import pickle
# 定义类Part
class Part:
number = 0
name = ""
def __init__(self, number, name):
self.number = number
self.name = name
def identify(self):
print("Part Number: %d"%(self.number))
print("Part Name: %s"%(self.name))
# 实例化part
part1=Part(111, "Spindle");
# Create a file to store the pickled object
# 创建文件存储pickled对象
objectRepository = open("ObjectFile.picl", "wb");
# Pickle/serialize the python object and store the bytes into a binary file
# 序列化Python对象并存储为二进制字节流
pickle.dump(part1, objectRepository, protocol=pickle.HIGHEST_PROTOCOL)
objectRepository.close()
# Unpickle/de-serialize the python object and print the attributes of the object
# 反序列化Python对象并打印对象属性
objectRepository = open("ObjectFile.picl", "rb",);
reconstructedObject = pickle.load(objectRepository)
# Print object attributes
# 打印对象属性
reconstructedObject.identify()1
2
- 运行结果:(venv) yuhao@fishmouse:~/Envs/venv/project$ python 819pickling_unpickling_example.py
Part Number: 111
Part Name: Spindle1
2
3
4
5
6
7
8
- 序列化的数据
```python
>>> with open('ObjectFile.picl','rb') as f:
... f.read()
...
b'\x80\x04\x959\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x04Part\x94\x93\x94)\x81\x94}\x94(\x8c\x06number\x94Ko\x8c\x04name\x94\x8c\x07Spindle\x94ub.'
==序列化==语法
pickle.dump(obj,file[,protocol])
- 序列化对象,将结果数据流写入到文件对象或者buffer中
参数protocol是序列化模式,一共有5种不同的类型,即(0,1,2,3,4);
- (0,1,2)早期的版本,默认值为0(表示以文本形式序列化),值为1或2(表示以二级制的形式序列化);
- (3,4)则是python3之后的版本
- 查看(3,4)
1
2
3
4
5import pickle
pickle.HIGHEST_PROTOCOL
4
pickle.DEFAULT_PROTOCOL
3pickle.dump():转换的字节流写入buffer中
示例:819pickle_dump_example.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65import pickle
import io
class Book:
title = ""
isbn = ""
parts = None
chapters = None
def __init__(self, title, isbn, parts, chapters):
self.title = title
self.isbn = isbn
self.parts = parts
self.chapters = chapters
def identify(self):
print("Title of the book: %s"%(self.title))
print("ISBN of the book: %s"%(self.isbn))
print("Parts are:")
for part in self.parts:
print(part)
print("Chapters are:%s"%(self.chapters))
class Part:
partName = ""
beginChapter = -1
endChapter = -1
def __init__(self, partName, beginChapter, endChapter):
self.partName = partName
self.beginChapter = beginChapter
self.endChapter = endChapter
def __str__(self):
stringRep = "%s"%(self.partName)
return stringRep
part1 = Part("Part 1", 1, 3)
part2 = Part("Part 2", 4, 5)
part3 = Part("Part 3", 6, 7)
bookTitle = "Book yet to be written";
bookISBN = "XXX-X-XX-XXXXXX-X";
bookParts = [part1, part2, part3]
bookChapters = ["Chapter 1", "Chapter 2", "Chapter 3",
"Chapter 4", "Chapter 5", "Chapter 6",
"Chapter 7"];
book = Book(bookTitle, bookISBN, bookParts, bookChapters)
# 创建buffer存储pickle对象
pickleBuffer = io.BytesIO()
print("Pickling of the object into the memory buffer started")
#
pickle.dump(book,pickleBuffer)
print("Pickling of the object into the memory buffer ended")
print("Pickled buffer beginning address:")
print(pickleBuffer.getbuffer())
print("Unpickling of the object from memory started")
#
unpickledBook = pickle.loads(pickleBuffer.getbuffer())
print("Unpickling of the object from memory ended")
print("Printing the attributes of unpickled object")
unpickledBook.identify()
pickle.dumps()参数
pickle.dumps(obj, protocol=None,*,fix_imports=True)
- 与pickle.dump()区别,pickle.dumps()方法不需要写入文件中,他是直接返回一个序列化的bytes对象
==反序列化==语法
pickle.load(file)
- 反序列化对象(将文件中数据解析为一个Python对象)
- ==注意==:load(file)时,要让Python能够找到类的定义,否则会报错
- 注意:参数file,必须是以二进制的形式进行操作(读取)
- 示例:819test_pickle.py
反序列方法pickle.loads()
参数如下:
pickle.loads(bytes_object, *,fix_imports=True, encoding=”ASCII”. errors=”strict”)
pickle.loads()方法是直接从bytes对象中读取序列化的信息,而非从文件中读取。示例如下:1
2
3
4
5import pickle
pickle.dumps([1,2,3])
b'\x80\x03]q\x00(K\x01K\x02K\x03e.'
pickle.loads(_)
[1, 2, 3]
1
2
3
4
5
6
7
8
9
10
11
12
13
14#load(file)时,要让Python能够找到类的定义,否则会报错
import pickle
class Person:
def __init__(self,n,a):
self.name=n
self.age=a
def show(self):
print(self.name+" "+str(self.age))
aa = Person("JGood", 2)
aa.show()
# del Person
f=open('p.txt','wb')
pickle.dump(aa,f,0)
f.close()1
2
3
4
5
6注释掉删除类对象操作,若未注释则会报错
del Person
f=open('p.txt','rb')
bb=pickle.load(f)
f.close()
bb.show()运行结果:
1
2
3(venv) yuhao@fishmouse:~/Envs/venv/project$ python 819test_pickle.py
JGood 2
JGood 2未注释结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14(venv) yuhao@fishmouse:~/Envs/venv/project$ python 819test_pickle.py
JGood 2
Traceback (most recent call last):
File "819test_pickle.py", line 15, in <module>
bb=pickle.load(f)
AttributeError: Can't get attribute 'Person' on <module '__main__' from '819test_pickle.py'>
[p.txt](p.txt)文件中数据存储格式:
```python
>>> with open('p.txt','rb') as f:
... f.read()
...
b'ccopy_reg\n_reconstructor\np0\n(c__main__\nPerson\np1\nc__builtin__\nobject\np2\nNtp3\nRp4\n(dp5\nVname\np6\nVJGood\np7\nsVage\np8\nL2L\nsb.'